Il 20 ottobre 2025, AWS ha sperimentato un importante outage nella Region North Virginia (us-east-1). Gli impatti si sono ripercossi su oltre 170 servizi e su numerosissimi clienti in tutto il globo. Insomma, questa è l'occasione giusta per imparare qualcosa. Illustrerò in breve cosa è successo e farò alcune considerazioni sugli hyperscaler, sul nostro mestiere e l'importanza di fare delle scelte.

L'outage di AWS del 20 ottobre
AWS gestisce migliaia e migliaia di endpoint per riuscire fornire un'infrastruttura globale scalabile e affidabile. Per farlo si affida fortemente alle automatizzazioni sulle modifiche DNS. L'architettura super-semplificata è la seguente ed è:
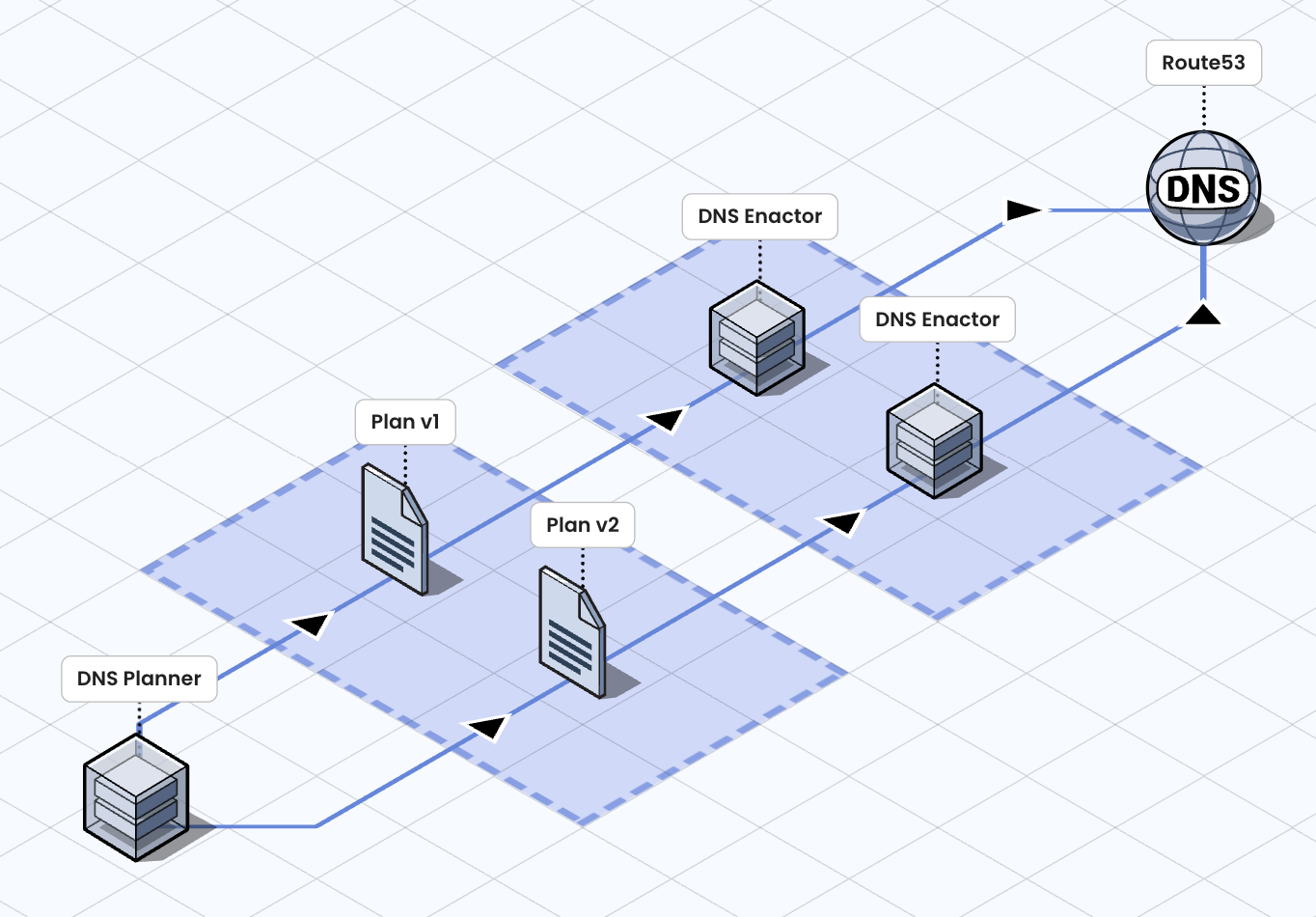
Notiamo due componenti principali:
- DNS Planner: genera un piano (Plan), ovvero un insieme di record DNS da modificare;
- DNS Enactor: applica un Plan su Route53, il servizio DNS di AWS;
L'infrastruttura prevede numerosi Enactor - dopotutto si tratta di un'architettura distribuita - e ciascuno di essi esegue una serie di verifiche per assicurarsi che il proprio Plan sia il più recente, prima di applicare i record DNS. Tuttavia, a causa di alcuni ritardi inusuali, si è verificata una situazione in cui più Enactor hanno considerato validi Plan diversi e hanno tentato di applicarli nello stesso intervallo temporale. In pratica, si è creata una race condition tra più Enactor e, come potete immaginare, ha finito per prevalere il Plan meno recente. Il risultato è che alcuni record relativi alla gestione di DynamoDB, previsti nel Plan più recente, sono stati sovrascritti con un valore vacante, causando problemi a cascata su numerosi servizi e Region, con impatti su migliaia di clienti.
I cloud provider sono davvero affidabili?
L'outage ha impattato non solo la Region del N. Virginia (us-east-1), ma anche le altre Region. Tant'è che numerose aziende europee hanno riscontrato dei problemi.
Consideriamo che la Region us-east-1 è un punto nevralgico per l’infrastruttura globale, perché qui ci sono i Control Plane di numerosi servizi globali, come STS, IAM, Identity Center - che interessano lo strato di auth -, Dynamodb Global Tables per la replica multi-region, i certificati TLS delle distribuzioni Cloudfront (la CDN di AWS) e altro ancora. Insomma, vuol dire che le Region, incluse quelle europee, hanno una dipendenza dalla Region del N. Virginia, che è anche la più vecchia, la più grande e quella che storicamente ha riscontrato più problemi. Il che fa pensare, considerando che AWS parla di eccellenza operativa e cell-based architecture.
Episodi di questo tipo fanno insinuare dei dubbi importanti: è corretto affidarsi ad un provider esterno, rinunciare al controllo della propria infrastruttura e restare impotenti? Sono dubbi che ovviamente possiamo avere anche in merito agli altri provider. Basti ricordare quella volta che GCP ha cancellato per sbaglio l’account di UniSuper, fondo pensionistico australiano. La causa è stato un errore umano del provider, ma a farne le spese è stato il cliente.
La verità è che i bias cognitivi sono dietro l'angolo e puntare il dito diventa semplicissimo, considerando soprattutto che episodi del genere mandano in iperventilazione i romantici del monolite e dell'on-premise, illusi di essere in una botte di ferro. Non metto in dubbio di essere anch'io vittima di bias e delle mie stesse certezze - sono pur sempre un essere umano -, ma mantenere uno spirito critico è fondamentale e mettere tutto in dubbio fa parte del mestiere. Hyperscaldr come AWS sono ad oggi soluzioni incredibilmente efficace e senza eguali per infrastruttura, competenze, compliance, sicurezza e gestione della comunicazione.
Una questione di scelte
Troppo spesso il cloud viene venduto o almeno percepito come quel luogo dove nulla di male può accadere, perciò, quando succede qualcosa, dei dubbi possono insinuarsi: è il mito dell'infallibilità. Ma il cloud non è magia: è solo un modello per acquisire e rilasciare risorse. Anzi, il cloud vuole dirci l'esatto opposto: reti, server e processi umani falliscono tutto il tempo. Quello che possiamo fare è studiare le tecniche per affrontare questi fallimenti e aumentare l'affidabilità dei nostri servizi.
Le possibilità del cloud riguardano la ridondanza, le strategie di disaster recovery, le strategie di testing e così via, implementando anche configurazioni multi-region e multi-provider. Certo è che soluzioni così efficienti, ma anche complesse, richiedono competenze altissime e costi esorbitanti.
Quello da cui bisogna sempre partire è uno studio della tolleranza sulla perdita dei dati e sull'operatività, che non può che essere diverso per ogni azienda. Se gestiamo business critici, forse è bene puntare a livelli altissimi. Se gestiamo un piccolo business, forse una soluzione più semplice e cost-effective è più indicata. Da considerare poi le soluzioni serverless, che grazie ad un modello pay-per-use, possono essere molto efficienti.
Insomma, il punto è che essere in cloud non basta. Adottarlo per davvero vuol dire avere consapevolezza delle posibilità, fare delle scelte e comprenderne (e accettare) le conseguenze. Concludo invitando ancora ad osservare con spirito critico e ricordando una delle frasi che mi piace citare spesso, estrapolata dal blog di Martin Fowler:"Software development is a young profession, and we are still learning the techniques and building the tools to do it effectively".