On October 20, 2025, AWS experienced a major outage in the North Virginia Region (us-east-1). The impact affected more than 170 services and countless customers across the globe. In short, this is the perfect opportunity to learn something. I’ll briefly explain what happened and share some thoughts about hyperscalers, our profession, and the importance of making informed choices.

The AWS outage of October 20
AWS manages thousands upon thousands of endpoints in order to provide a scalable and reliable global infrastructure. To achieve this, it relies heavily on automation for DNS changes. The ultra-simplified architecture is as follows:
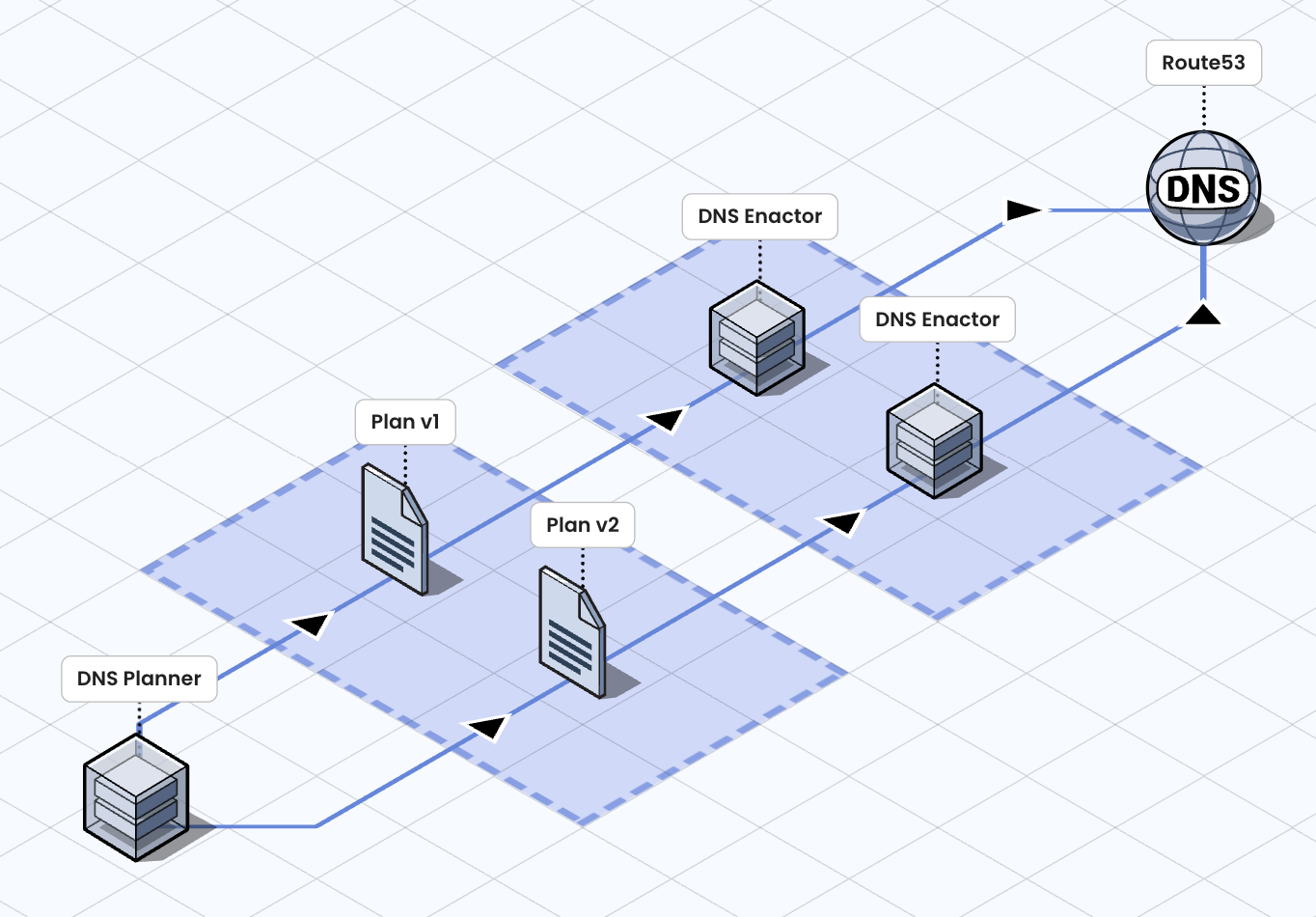
We can identify two main components:
- DNS Planner: generates a plan (Plan), that is, a set of DNS records to be modified;
- DNS Enactor: applies a Plan to Route53, AWS’s DNS service;
The infrastructure includes numerous Enactors — after all, it’s a distributed architecture — and each of them performs a series of checks to ensure that its own Plan is the most recent before applying DNS records. However, due to some unusual delays, a situation occurred in which multiple Enactors considered different Plans to be valid and attempted to apply them within the same time window. In practice, a race condition arose among several Enactors and, as you can imagine, the less recent Plan ended up prevailing. As a result, some records related to DynamoDB management — included in the latest Plan — were overwritten with empty values, triggering cascading issues across multiple services and Regions, and impacting thousands of customers.
Are cloud providers really reliable?
The outage affected not only the N. Virginia Region (us-east-1) but also other Regions. In fact, many European companies also experienced issues.
Consider that the us-east-1 Region is a critical hub for the global infrastructure, as it hosts the Control Planes of many global services such as STS, IAM, Identity Center — which handle the authentication layer — DynamoDB Global Tables for multi-region replication, TLS certificates for CloudFront distributions (AWS’s CDN), and more. In short, this means that the Regions — including the European ones — depend on a single Region, which also happens to be the oldest, the largest, and the one that has historically experienced the most issues. This is quite thought-provoking, especially considering that AWS promotes operational excellence and cell-based architecture.
Incidents like this raise important questions: is it right to rely on an external provider, give up control of your own infrastructure, and remain powerless? Of course, similar doubts can also apply to other providers. Just remember the time when GCP accidentally deleted UniSuper’s account, an Australian pension fund. The cause was human error on the provider’s side — but it was the customer who paid the price.
The truth is that cognitive biases are always lurking, and pointing fingers becomes all too easy — especially since events like this send the romantics of the monolith and on-premise enthusiasts into a frenzy, convinced they’re safe in their ironclad setups. I don’t deny being subject to biases and my own certainties — I’m human, after all — but maintaining a critical mindset is essential, and questioning everything is part of the job. Hyperscalers like AWS remain, to this day, incredibly effective and unmatched solutions in terms of infrastructure, expertise, compliance, security, and communication management.
A matter of choices
Too often, the cloud is sold — or at least perceived — as a place where nothing bad can ever happen, so when something does, doubts begin to arise: it's the myth of infallibility. But the cloud is not magic: it’s simply a model for acquiring and releasing resources. In fact, the cloud teaches us the exact opposite — networks, servers, and human processes fail all the time. What we can do is study techniques to deal with these failures and improve the reliability of our services.
The options involve redundancy, disaster recovery strategies, testing strategies, and so on — including multi-region and multi-provider configurations. Of course, such efficient yet complex solutions require very high expertise and significant costs.
What you should always start with is an assessment of your tolerance for data loss and operational downtime — which will inevitably differ for each company. If you manage critical business operations, you should probably aim for the highest possible levels of resilience. If you run a small business, a simpler and more cost-effective solution might be more appropriate. It’s also worth considering serverless solutions, which, thanks to their pay-per-use model, can be highly efficient.
In short, the point is that simply being “in the cloud” is not enough. Truly adopting it means understanding the possibilities, making informed choices, and recognizing (and accepting) their consequences. I’ll conclude by inviting everyone to keep a critical eye — and by quoting one of my favorite lines, taken from Martin Fowler’s blog:"Software development is a young profession, and we are still learning the techniques and building the tools to do it effectively."